

About a month before CES 2015 I wrote an in-depth blog article about our PowerVR Series7XT GPUs, presenting the industry-leading performance efficiency gains made since Series6XT and giving an overview of their desktop-class features.
Today I’m very excited to announce GT7200 Plus and GT7400 Plus, two new GPUs that represent the next evolution of our Rogue architecture. These new graphics processors are part of the PowerVR Series7XT Plus family, our state-of-the-art, high-end GPUs aimed at the premium and mid-range segments of the consumer electronics market.
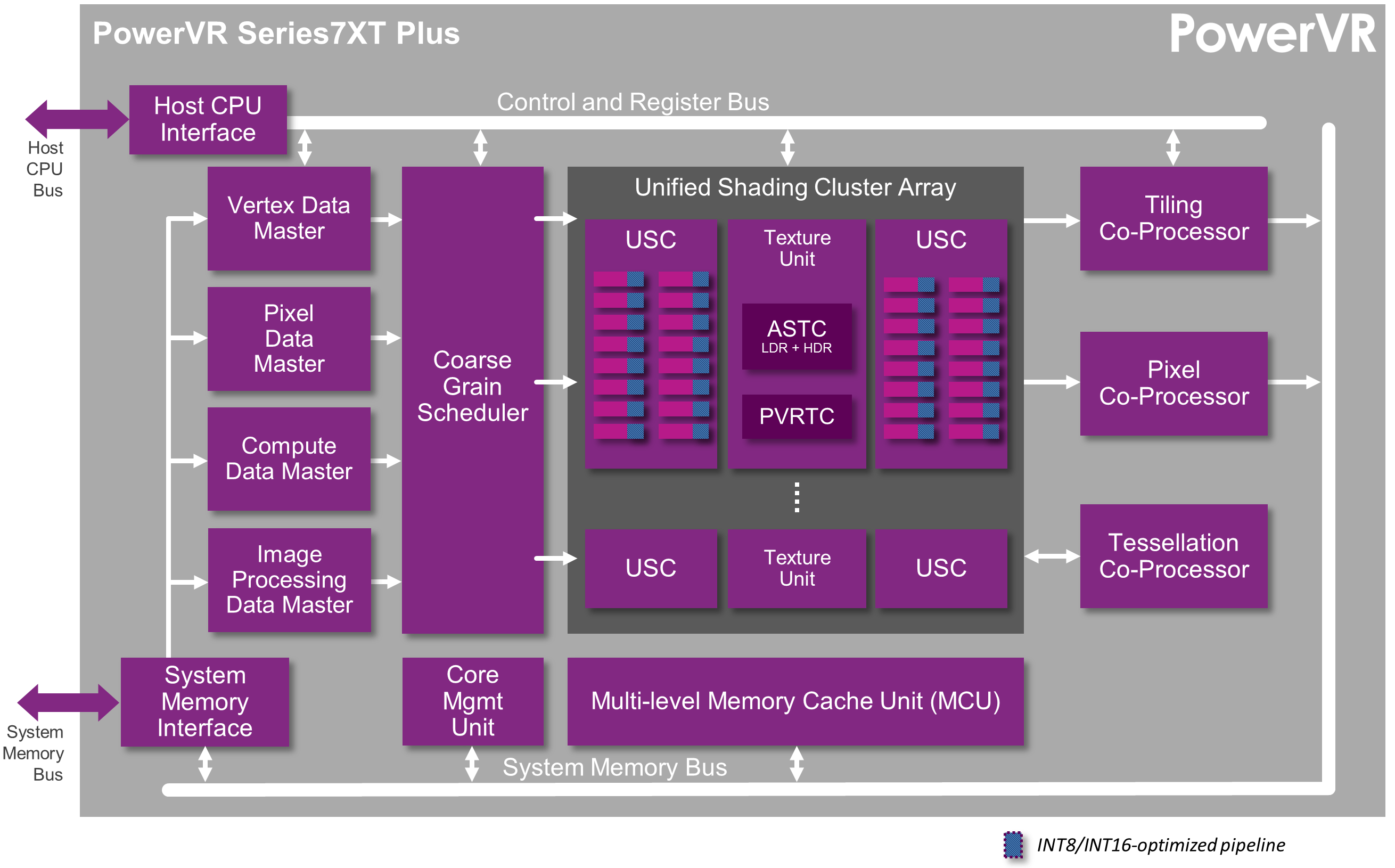 PowerVR Series7XT Plus GPUs feature an improved integer pipeline for vision processing
PowerVR Series7XT Plus GPUs feature an improved integer pipeline for vision processing
GT7200 Plus is a dual-cluster configuration sporting 64 ALU cores while GT7400 Plus is a quad-cluster graphics processor counting 128 ALU cores. Both designs retain the full feature set of their Series7XT counterparts (e.g. OpenGL® ES 3.2 and design for Vulkan™* support, hardware virtualization, advanced security etc.) while also introducing a number of new features aimed at vision and heterogeneous computing platforms.
The headline features are the introduction of a new integer pipeline for vision-related applications and the added hardware support for the OpenCL™ 2.0** compute API.
In addition, we’ve made significant microarchitectural enhancements that improve system performance and reduce power consumption; these include:
- Support for the latest bus interface features including requestor priority support
- Doubled memory burst sizes, matching the latest system fabrics, memory controllers and memory components
- Tuned the size of caches and improved their efficiency, leading to a ~10% reduction in bandwidth
Up to 4x performance in vision applications
The new PowerVR Series7XT Plus GPUs deliver a significant leap in integer performance, which is particularly useful in computational photography and other vision-related applications (e.g. deep learning).
The block diagram below presents the architecture of the new Series7XT Plus ALUs:
 The Series7XT Plus USC features a new integer pipeline optimized for computer vision applications
The Series7XT Plus USC features a new integer pipeline optimized for computer vision applications
Whereas previous Rogue GPUs support only INT32 formats, Series7XT Plus GPUs can make use of the new INT16 and INT8 data paths to boost performance by up to 4x for applications where the greater numeric range does not make sense, for example in OpenVX kernels or other vision oriented intrinsics.
In addition, a new Image Processing Data Master takes care of the geometry- and tiling-free rendering tasks suitable to 2D graphics and image processing applications, leading to more power savings and system-level performance optimizations.
OpenCL 2.0 support
The Series7XT Plus family sees the Rogue architecture implementing the hardware features needed to support the OpenCL 2.0 API for heterogeneous computing.
Further improvements in shared virtual memory support enable direct sharing of pointers between the main CPU and PowerVR Series7XT Plus GPUs, eliminating the need for data copies and reducing system-wide latency.
Series7XT Plus GPUs can also adapt to the data requirements of OpenCL 2.0 kernels on the fly, creating new GPU threads dynamically and with no CPU interaction (i.e. dynamic parallelism).
 CPU parallelism simplifies GPU programming for compute applications
CPU parallelism simplifies GPU programming for compute applications
Dynamic parallelism simplifies the GPU programming paradigm, reduces CPU overhead, and improves power consumption and execution efficiency for a broad set of compute algorithms.
Computer vision and heterogeneous systems
Computer vision is quickly emerging as the new battleground for heterogeneous architectures. At a recent Embedded Vision Alliance meeting, Chinese search giant Baidu presented a Deep Neural Network (DNN) app that allows users to identify thousands of objects directly from the camera input stream in real-time.
Baidu implemented their neural network on a mobile application processor, using a PowerVR Rogue GPU to match images against a database of thousands of objects in real-time.
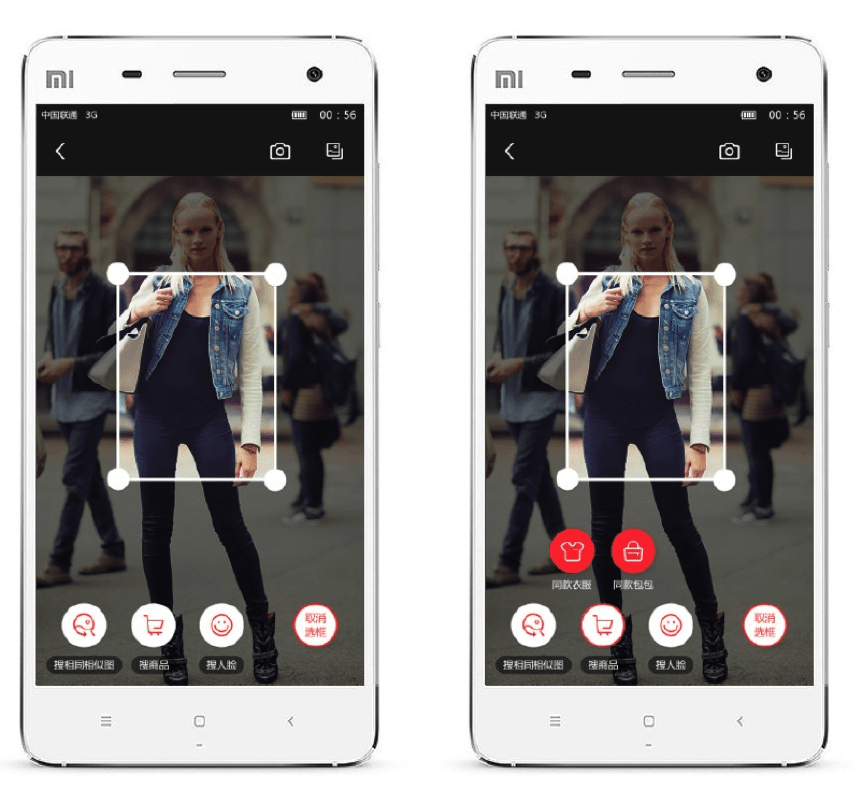 Baidu uses deep learning algorithms running on PowerVR GPUs for image classification
Baidu uses deep learning algorithms running on PowerVR GPUs for image classification
By combining techniques related to computer graphics and deep learning algorithms, vision applications present a richer and more meaningful representation of the world.
However, most of the mobile-oriented chips designed today do not have dedicated vision hardware; this is where PowerVR Series7XT Plus GPUs (and other Rogue graphics processors) come in to save the day.
Rogue GPUs are fully programmable processors that support powerful and flexible low-level APIs for graphics, compute and vision applications. For example, computer vision programmers can choose OpenCL or OpenGL ES Compute Shaders to implement their own low level vision kernels on PowerVR Rogue GPUs, or they can access the high performance compute capability through Imagination’s OpenVX implementation which recently achieved conformance with version 1.0.1.
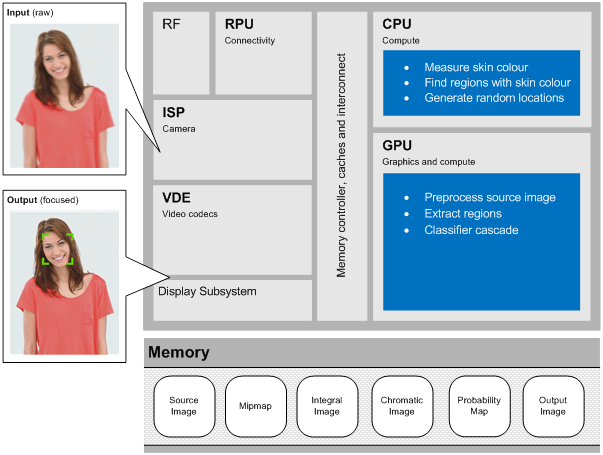
Features that benefit from hardware-acceleration on Rogue GPUs include image classification, face, body and gesture tracking, smart video surveillance, HDR rendering, advanced driver assistance systems (ADAS), object and scene reconstruction, augmented reality, visual inspection, robotics and more.
For more news and announcements related to PowerVR, keep coming back to our blog and follow us on Twitter (@ImaginationTech, @PowerVRInsider, @GPUCompute).
Editor’s Note
* PowerVR Seriex7XT Plus GPUs are based on an internal draft Khronos specification, which may change prior to final release. Conformance criteria for this specification have not yet been established.
** PowerVR Seriex7XT Plus GPUs are based on published Khronos specifications, and are expected to pass the Khronos Conformance Testing Process. Previous generation PowerVR Rogue GPUs have already achieved conformance. Current conformance status can be found at www.khronos.org/conformance.
OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos.
OpenGL is a registered trademark and the OpenGL ES logo is a trademark of Silicon Graphics Inc. used by permission by Khronos.



