

In previous blog posts, we have demonstrated using neural networks to do things such as object recognition and digit recognition. In this post, we will demonstrate a more practical example of vision, AI and machine learning running on PowerVR GPUs. This demo is showing how we can utilise the processing power of hardware such as the GPU to take input from a camera and run that input through multiple convolutional neural networks (CNNs).
The networks we are using return a number of locations of faces in the image and a “descriptor” for these faces. We have trained these networks on the FDDB (5171 faces) and VGG (images of 2622 different identities) data sets. You can see the demo running below using the PowerVR deep neural network (DNN) library, both developed by the PowerVR research team and vision team. The library takes high-level instructions, weights and biases and turns them into data that the GPU can consume in an efficient manner. We then use OpenCL to process the network in real-time.
The demo is running on an Acer Chromebook, with a MediaTek MT8173 SoC equipped with a PowerVR GX6250 GPU running at 455 MHz. We have managed to run the face detection demo on battery power for an impressive six hours after a full charge, reinforcing the power efficiency and performance of the PowerVR GPU.

In the above image, you can see the demo detecting three user’s identities at once.
The demo is a real-world example of how face detection and identification could be used in practice. It mimics a theoretical TV system that recognises the users and automatically brings up content that’s suitable and relevant for them.
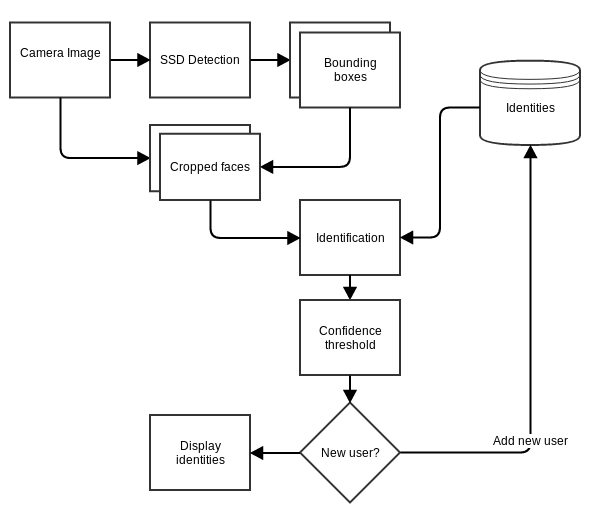
We first detect any faces in the image that comes back from the webcam using a variation of the GoogLeNet single shot detection (SSD) neural network. This gives us a rectangle around each face. We isolate the faces and run another neural network on each of those locations. This instantly gives us back a “descriptor”. This descriptor should be similar for each captured frame of the same face. It also means that adding identities to the system is trivial. You can see in the demo above how we identify a face we have not seen before, use the descriptor and then recognise this face the next time that descriptor is seen in the network again.
Below is a diagram of how this demo works:
We can imagine many uses for this technology, such as for smart TVs that already have hardware capable of running a neural network. For example, a user could be registered and the system will automatically load that user’s favourite films, apps or shortcuts as they sit down to watch, helping to improve the user experience.
Another potential use could be to check when a user is looking directly at the device, bringing the possibility of tracking viewing habits and interest in what is being shown. This could potentially be used for marketing purposes or for enabling the personalisation of recommendations without the need for user interaction.
Another example would be a smart doorbell that alerts the user to known faces ringing the doorbell, providing a custom tune for each user. Some of these products already exist, such as this AI-powered security camera, for example.
This is just one demo of how image recognition works efficiently and quickly on our PowerVR GPUs and we look forward to keeping you updated on the blog on our progress in advanced performance on machine learning and PowerVR.
You can follow Imagination on social media on Twitter @ImaginationTech.



