

In an article published recently I provided an overview of the most common metrics used to measure the relative performance of GPUs. I also covered how these metrics are reflected in some of the most popular graphics benchmarks available to silicon vendors, OEMs and consumers.
Today I am going to offer you a quick how-to guide for choosing the perfect PowerVR GPU for your next-generation SoC design. This article is based on a presentation given by Kristof Beets, our director of business development for PowerVR graphics, at a recent Imagination Summit event in Taiwan.
We currently have many options available if you are looking for a best-in-class GPU. Our PowerVR graphics solutions scale from wearable and IoT-oriented designs where low power and reduced area are critical all the way up to multi-cluster GPUs that break the TFLOPS range and offer ultimate performance for graphics and compute.
When looking at selecting the building blocks of a processor it’s easy to get stuck in the details. To make things easier, there are several questions you can ask yourself that should help you understand your high-level product requirements:
- What products do you want to target?
- Who are your main competitors?
- What are the must-have technical requirements?
- Are there any technical or business limitations?
- Are there any historical issues to avoid?
Balancing requirements with reality
Feature sets and performance points are evolving rapidly for mobile GPUs; for example, PowerVR GX6650 features 192 ALU cores and delivers desktop PC-class performance. Graphics APIs are also developing at an accelerated rate: while OpenGL ES 3.0 took just over five years to be released, OpenGL ES 3.1 arrived only a year later. More recently, the Khronos Group announced yet another project to define a future open standard for high-efficiency access to graphics and compute on modern GPUs. Clearly the software side of graphics is also progressing at an ever faster pace.
In an ideal world everything runs at maximum performance without consuming any power and occupying almost no silicon area. However, chipsets are built in the real world and therefore come with trade-offs. Additionally, most markets do not require desktop-class feature levels and instead focus almost exclusively on efficiency (i.e. balancing performance and features versus area and power costs). I’m sure many of you can relate to the illustration below: 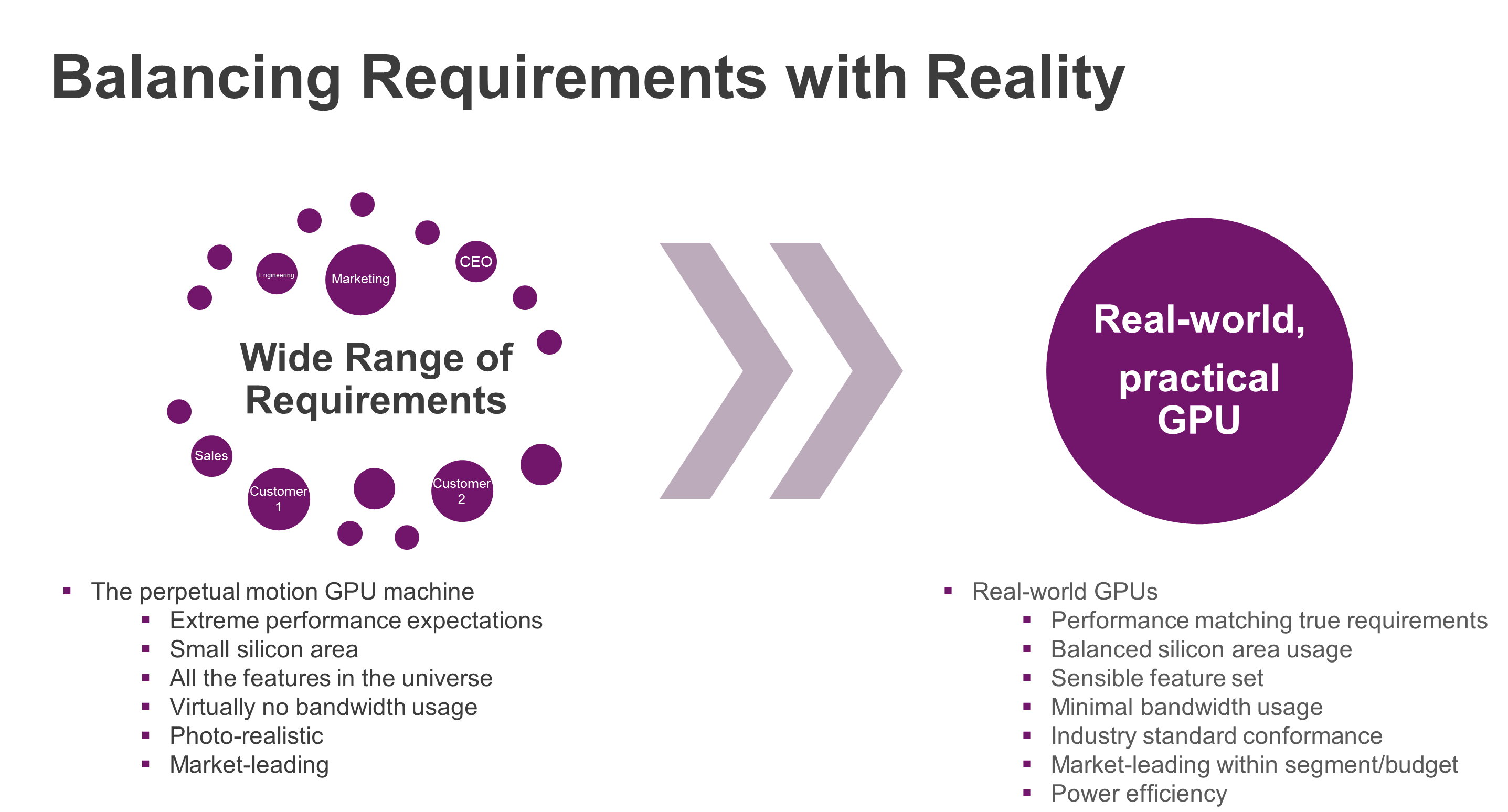
SoC designers always try to find the right balance between performance, power, area and feature set
Considering the points mentioned above, let’s review some of the most important requirements in mobile and embedded applications and how we address them.
Memory bandwidth
Geometry throughput (explained in A consumer’s guide to graphics benchmarks) is perhaps one of the most over-abused metrics in graphics. It is easily influenced by marketing hype and often leads to over-design issues. We’ve looked carefully at the requirements of multiple markets and analyzed real-world scenarios to make the design decisions behind our PowerVR Rogue GPUs.
In the bandwidth analysis presented below, notice how a claimed throughput of 1000 MTri/s (million triangles per second) simply cannot be sustained by the typical memory bandwidth available to a mobile processor (sustained rates at best of 10 to 20 GBytes/s).
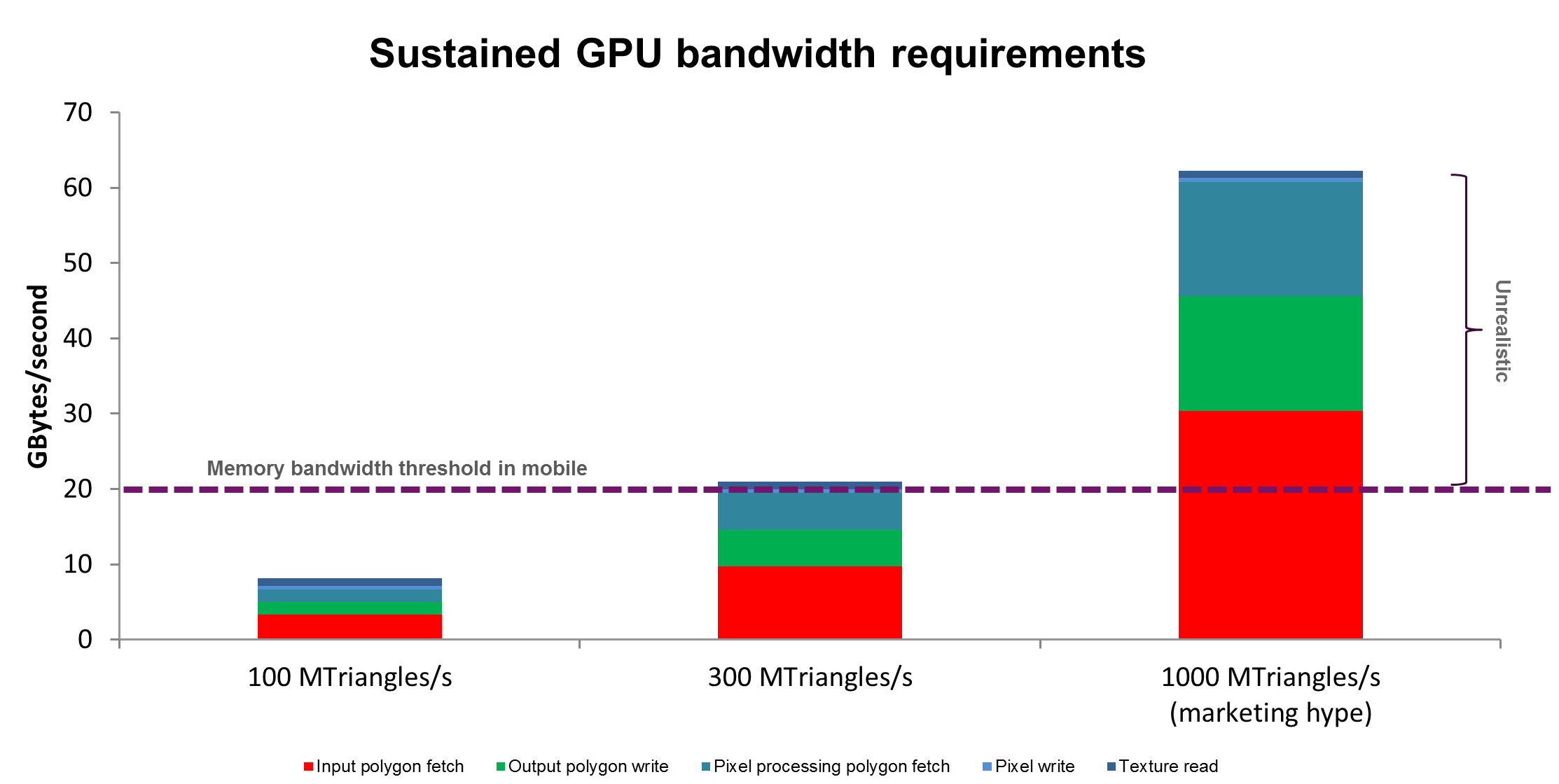 Claimed throughputs above 300 MTriangles/s cannot be sustained by the typical memory bandwidth available in mobile
Claimed throughputs above 300 MTriangles/s cannot be sustained by the typical memory bandwidth available in mobile
This is why we’ve designed the front-end of PowerVR Rogue GPUs to scale intelligently when it comes to geometry throughput and offer sensible performance points to vendors targeting mobile and embedded markets rather than a bloated design with high theoretical specs.
Power consumption
Some markets are very sensitive to power consumption (e.g. wearables) while others are less driven by it (e.g. automotive, 4K smart TVs). Usually, managing the power budget of a chip is not a localized concern but a system-level requirement which varies depending on various scenarios.
In most modern workloads today, power management takes a heterogeneous approach (i.e. the power budget is shifted between multi-core processors, graphics, video, etc.) and is usually controlled by software mechanisms including power gating and DVFS.
PowerVR GPUs are designed for power efficiency and implement a number of unique technologies to reduce power consumption:
- PowerGearing: an innovative suite of power management mechanisms that lead to sustained performance within fixed power and thermal envelopes. PowerGearing enables fine-grained control of all GPU resources and allows dynamic, demand-based scheduling of shading clusters and other processing blocks.
- PVR3C: a trio of optional compression allows trade-off between area versus power consumption and bandwidth use. You can read more about PVR3C here.
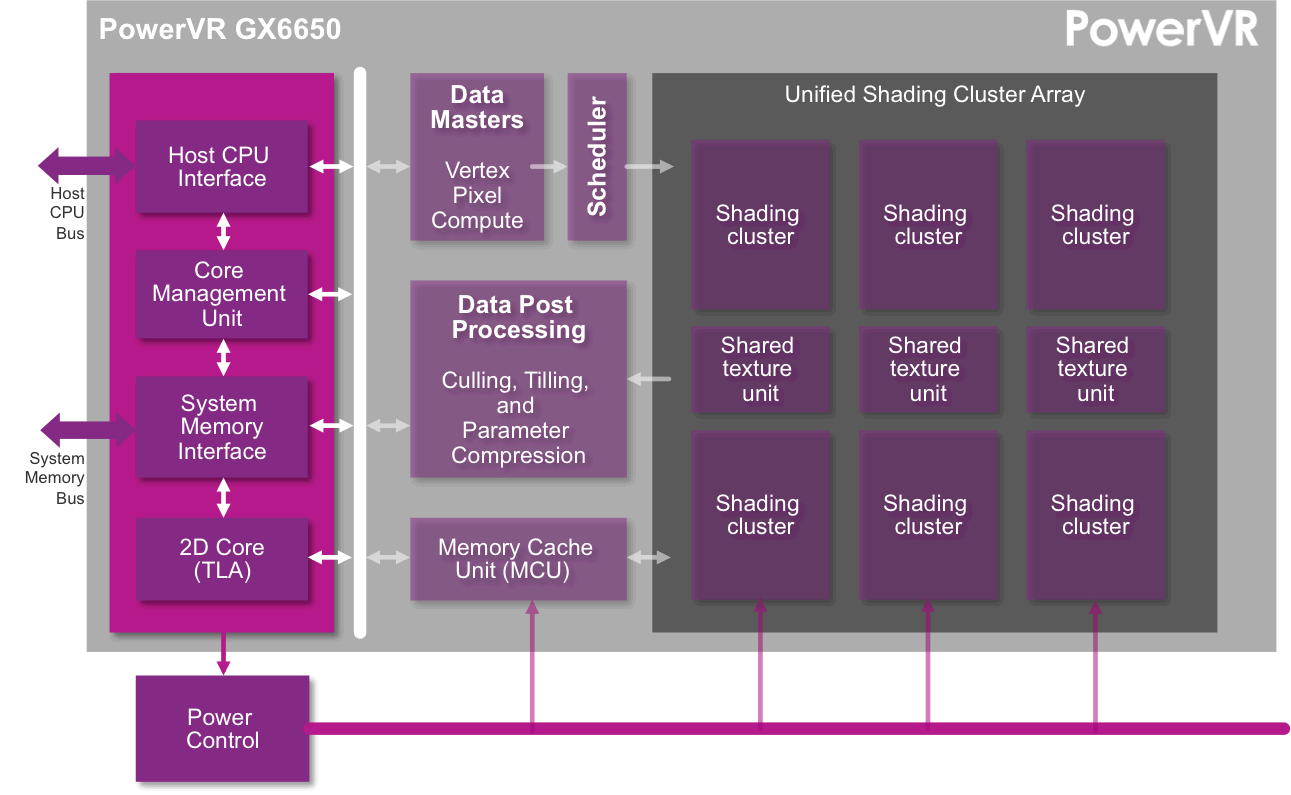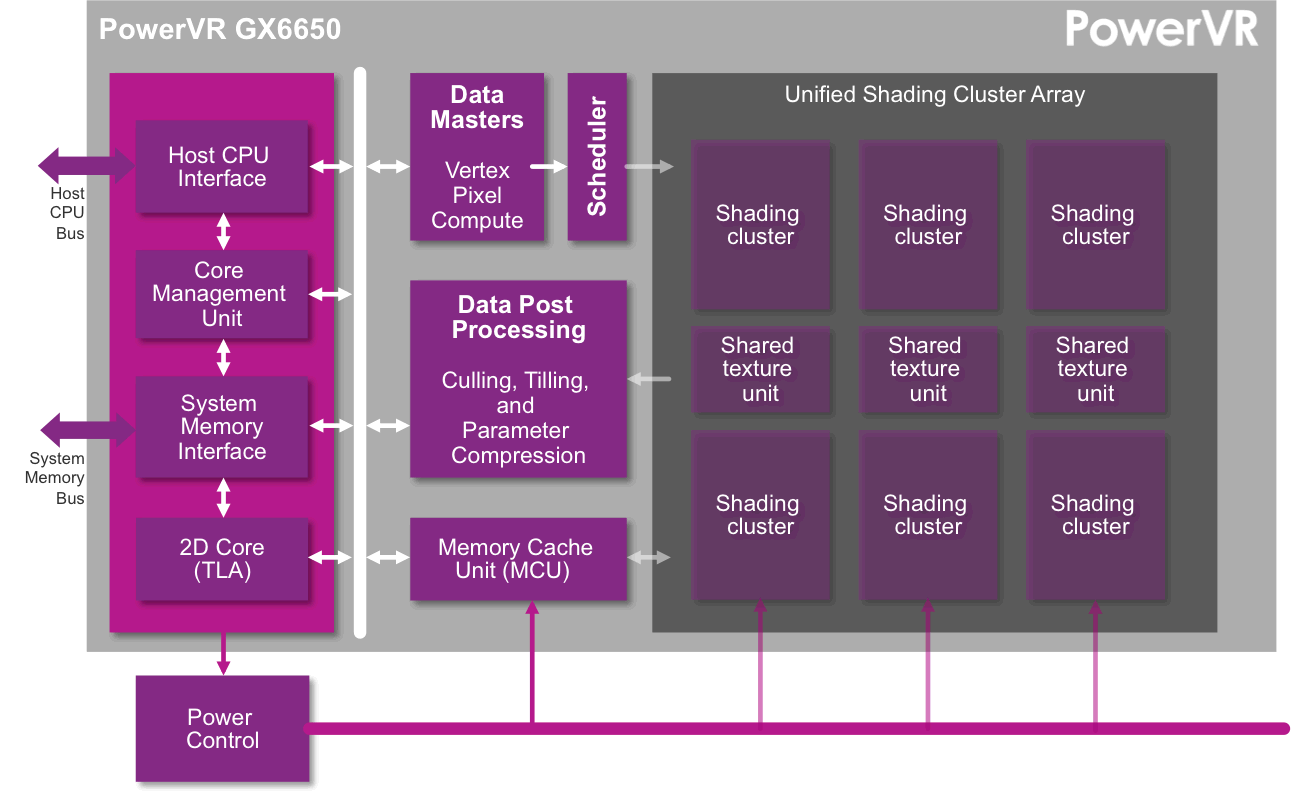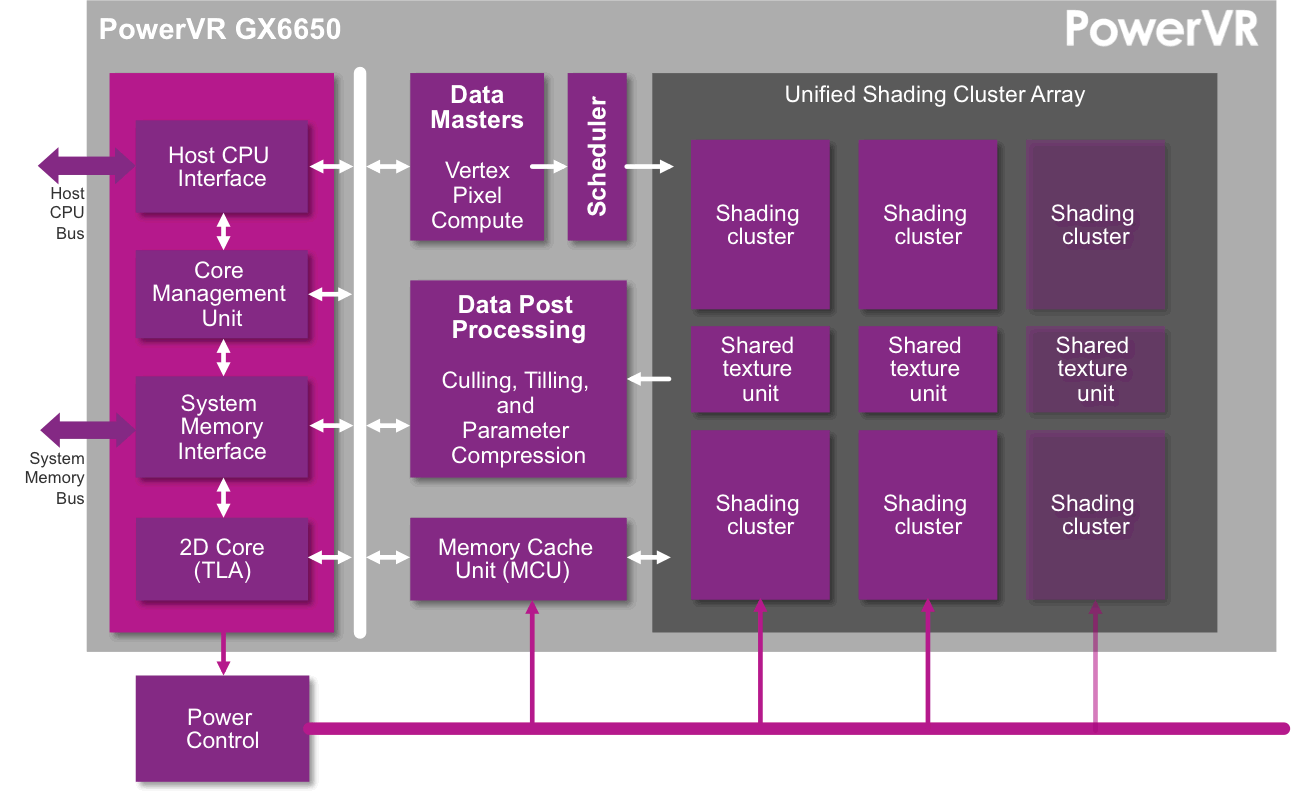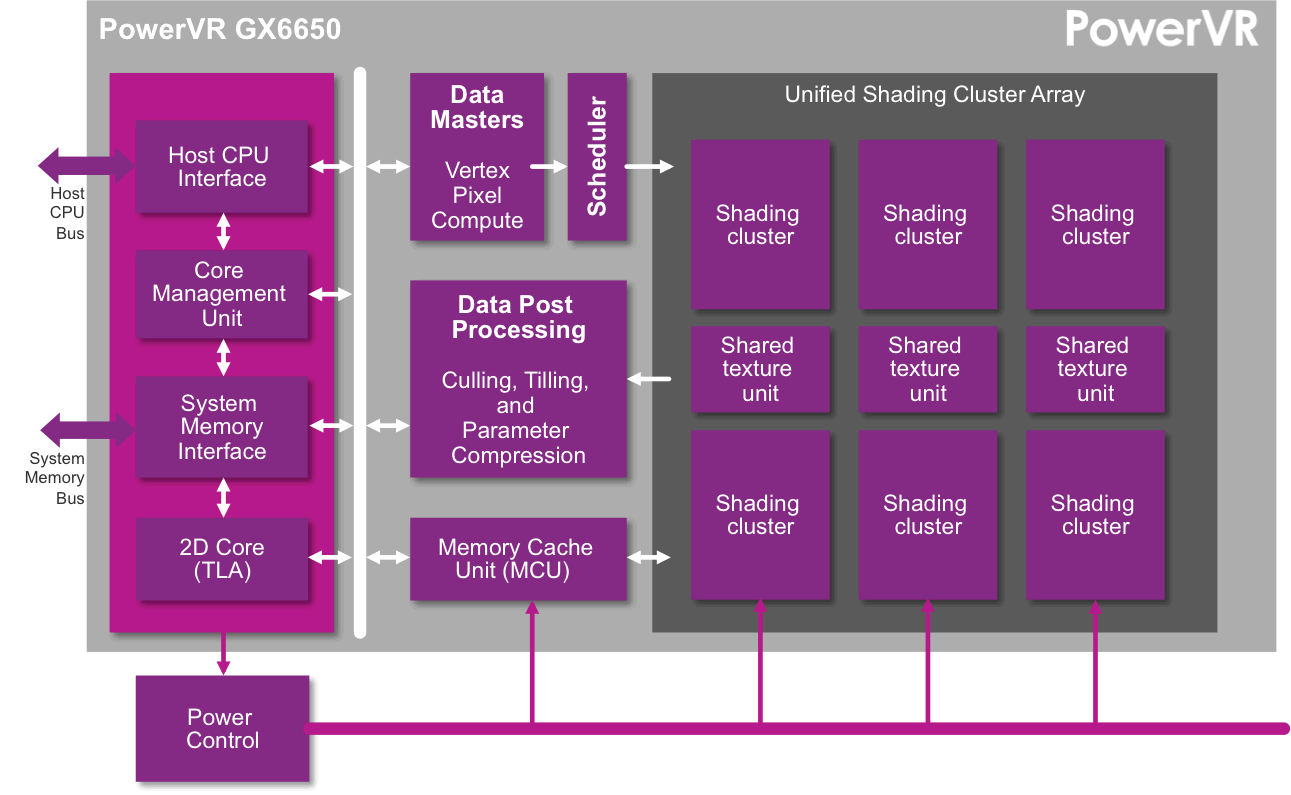
PowerGearing implements advanced power management
Silicon area
The target cost of a chip determines its silicon area budget therefore an over-spec’d GPU may price an SoC out of its target segment. Since GPUs represent a growing percentage of die space on a chipset, picking an area-efficient PowerVR graphics processor can help reduce costs significantly.
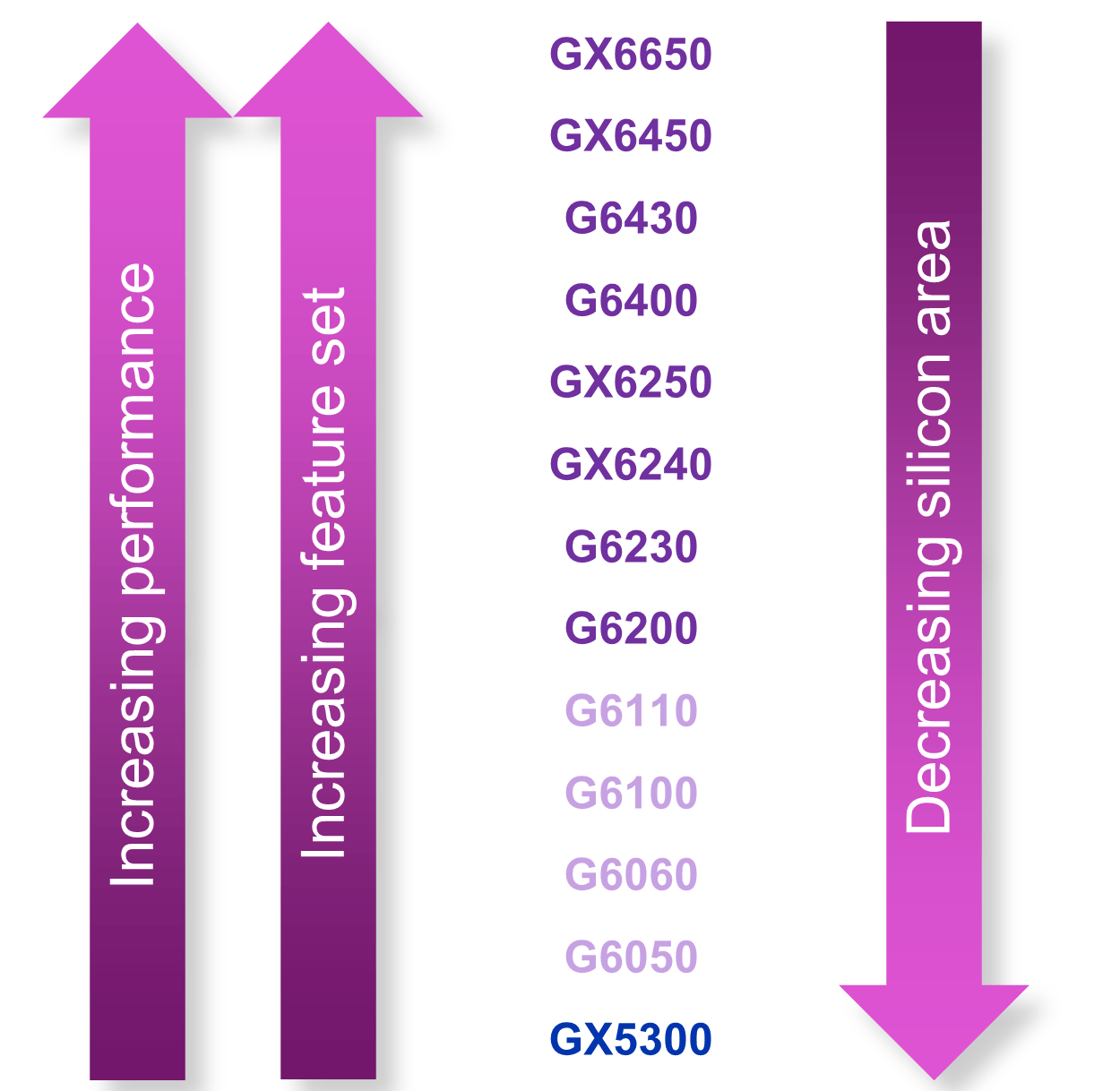 We offer an extensive range of graphics processors that scale extremely well in area
We offer an extensive range of graphics processors that scale extremely well in area
For designs where area is the main driver, we have a wide range of scaling options available across features and performance (e.g. clusters) allowing us to deliver the optimal solution for each target market or application. The chart below describes the relationship between performance and features versus area:
The selection process
An overview of the typical selection process of a PowerVR GPU is presented below:
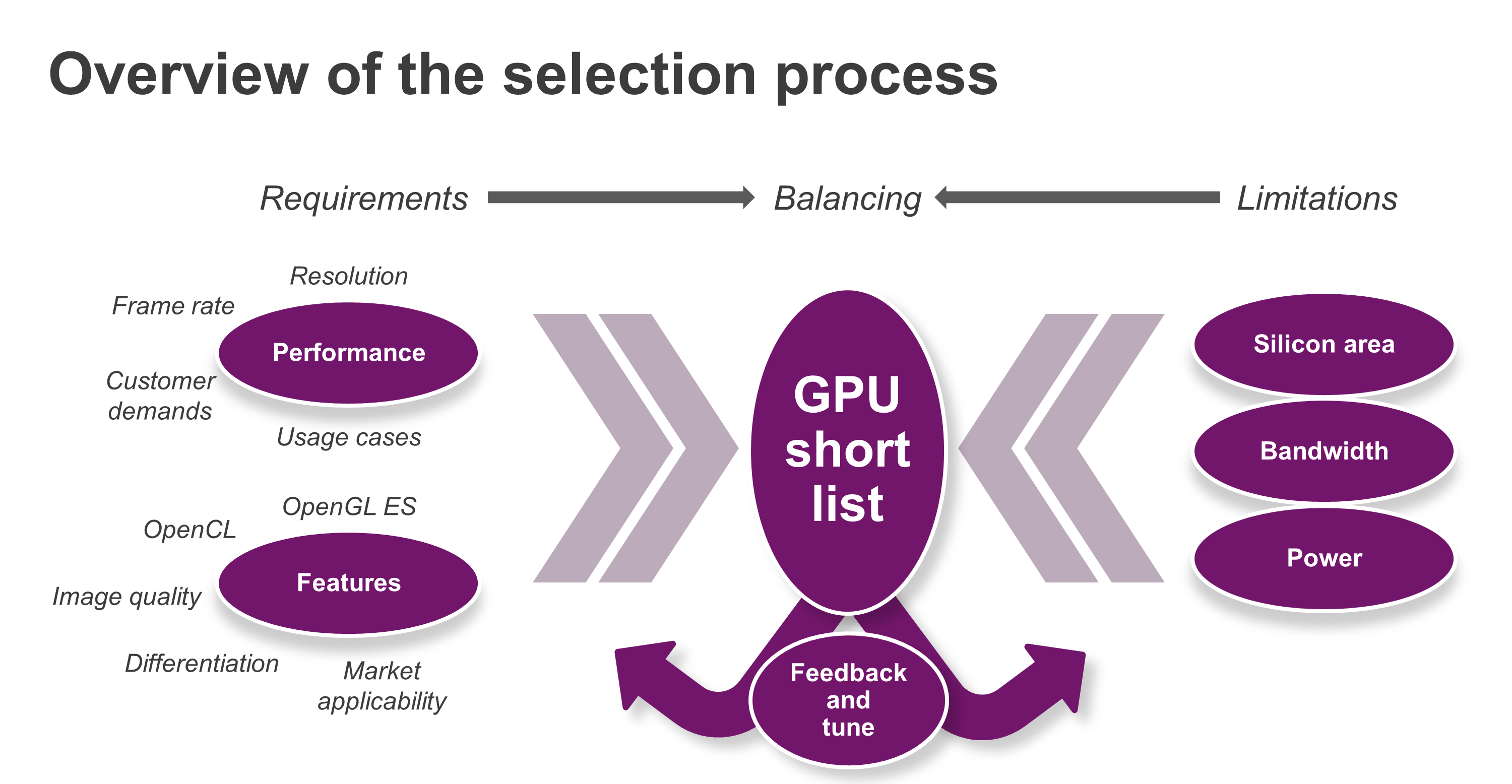 The typical selection process for a mobile GPU
The typical selection process for a mobile GPU
Let’s apply this algorithm to two case studies: a wearable SoC for a smartwatch and a chipset for an affordable 4K smart TV.
Case study #1: A wearable SoC for a smartwatch
The main factor that influences processor selection for wearables is low power consumption. To address the current requirements for wearable electronics, we’ve recently released PowerVR GX5300, a proven, small and very power efficient GPU with full OpenGL ES 2.0 support.
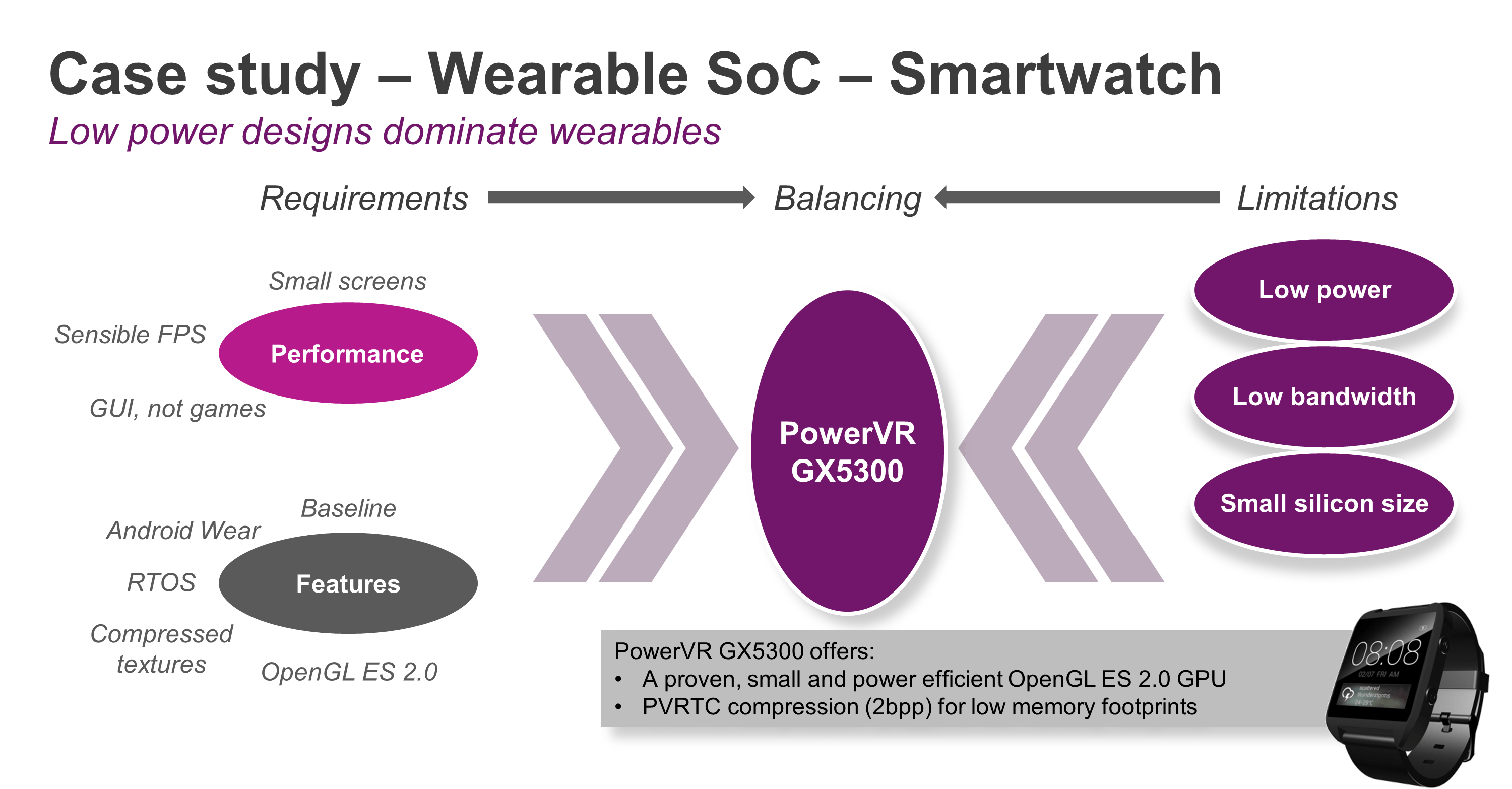 The selection process for a mobile GPU inside a smartwatch
The selection process for a mobile GPU inside a smartwatch
PowerVR GX5300 also includes PVRTC, a 2bpp (bits per pixel) compression standard that reduces memory footprint and bandwidth significantly, helping to reduce power consumption and memory footprint constraints.
Case study #2: Affordable 4K smart TV chipset
When it comes to choosing a processor for an affordable smart TVs, cost is the dominant factor. This means that every on-chip processor, including the GPU, must be designed for optimal silicon area.
However, 4K automatically implies very high fillrates and bandwidth therefore you need the best of both worlds: a GPU that is small yet offers superior rendering for user interfaces – and maybe some casual gaming, with minimal bandwidth usage.
 The selection process for a mobile GPU inside an affordable 4K DTV
The selection process for a mobile GPU inside an affordable 4K DTV
PowerVR G6110 is an ideal fit for affordable 4K smart TVs, offering OpenGL ES 3.1 support, PVRIC2 lossless frame buffer (de)compression and PVRTC2 texture compression.
Conclusion
PowerVR GPUs have a large number of competitive strengths, making them suitable for many markets. We offer solutions that scale optimally and support design optimization kits that aid integration.
What market segment are you interested in? What would you add to our selection process? Leave us a comment in the box below.
Make sure you also follow us on Twitter (@ImaginationTech) for the latest news and announcements from our ecosystem.



