Update: We have now announced our first Furian-based core: the PowerVR Series8XT GT8525: find out more details here.
Things move fast in the world of graphics. We announced the first PowerVR Rogue licensable GPU IP in 2012, a year after revealing the microarchitecture, and we’d been working on it for some time before that. Six years on from peeling back the covers on PowerVR SGX’s successor and it’s still going strong; you’ll find its most recent incarnations today at the heart of Series7XT and Series8XE. GPUs might be one of the fastest moving parts in today’s modern application processors in terms of their performance and feature set, but underlying that there’s a longer timespan to the whole endeavour of creating and shipping one. Especially when it comes down to the real nuts and bolts of the ideas embodied in its microarchitecture.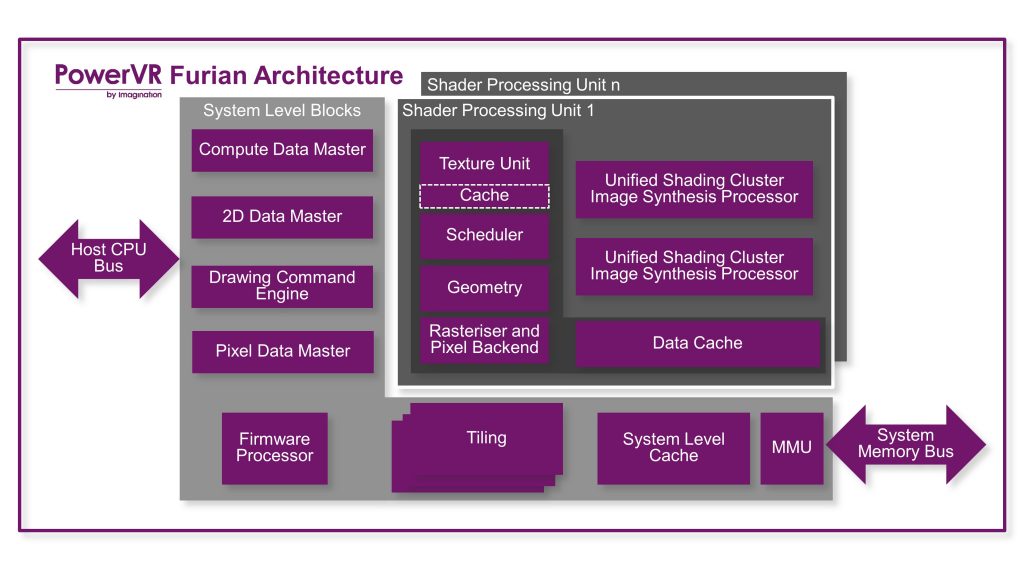 GPUs enjoy and exploit the lack of a standard instruction set architecture, or ISA, in order to have a quickness to their development. Without something like ARMv8 or x86 to implement, GPUs are naturally freer to experiment and innovate, and change happens in GPUs more rapidly than the CPUs of today. Higher level APIs let that happen, sitting on top of a malleable driver that moulds and shapes itself along with the hardware’s continued evolution. And evolution it honestly is; despite not having a standard ISA to implement, and the safety net of a driver and high-level APIs, GPU architects rarely throw out the champagne with the cork.
GPUs enjoy and exploit the lack of a standard instruction set architecture, or ISA, in order to have a quickness to their development. Without something like ARMv8 or x86 to implement, GPUs are naturally freer to experiment and innovate, and change happens in GPUs more rapidly than the CPUs of today. Higher level APIs let that happen, sitting on top of a malleable driver that moulds and shapes itself along with the hardware’s continued evolution. And evolution it honestly is; despite not having a standard ISA to implement, and the safety net of a driver and high-level APIs, GPU architects rarely throw out the champagne with the cork.
So while we’re announcing a new graphics microarchitecture today, our first since Rogue, there’s plenty that’ll feel familiar to students of today’s designs. It goes without saying that Furian is still a tile-based deferred renderer (TBDR). PowerVR absconding from that battle-tested, market-leading aspect of our design would be like throwing out the ’96 Krug Clos d’Ambonnay. If you’re not familiar with what a TBDR is or how it works, we’ve got you covered with two articles. One walks you through the tile-based aspect and the other explains what the deferred bit means. Both still apply to Furian in broad terms, so they’ll get you up-to-speed on the magic behind how we execute.
With our microarchitecture’s pièce de résistance intact, let’s take a tour through the key really new bits of Furian, comparing and contrasting against a backdrop of Rogue, to hopefully get a feel for the challenges the architects and designers took on when putting it together. You don’t need to rub too many brain cells together to figure out that we’d want to enhance performance and efficiency in a way that justifies the investment in something new, but there’s always a method to the madness of constant PPA (power, performance and area) improvements. Maybe we can tease that out of this trip through the microarchitectural highlights. Let’s start with scaling.
Scaling
Imagine you’ve designed a whole GPU, top to bottom. You’ve probably at the very least built something to handle incoming geometry, a rasteriser to turn that into pixels, a texture unit, something to get finished pixels out of the GPU and onto the screen at the end, and these days probably some kind of unified compute core to do the shading parts of today’s workloads.
Today, those shading parts are at least vertex, pixel and compute. And if we keep going, because each vertex, pixel and compute work item is usually somewhere on the spectrum of partially to fully independent, your compute core has likely baked in at least some level of parallelism. So we’ve got a parallel, unified shader core and some other bits needed to handle some focused graphics tasks using that core. Now imagine you need to scale its performance up. What do you do?
The easiest thing to do is to just duplicate the entire GPU one or more times, with some extra logic to distribute work to each one. And that’s fine, but no matter the balance of resources in the base GPU design, you’ll always go out of ‘real-world’ workload balance in a larger design if all you’re doing is just copying the entire thing multiple times. That’s not to say it’s not a valid approach; we went exactly that way with Series5XT. If you’ve ever heard of something like SGX543MP4, that’s four full SGX543 GPUs with some helper logic to glue them all together and present them to the system as a single GPU.
But if you want to scale total performance past a certain point, that approach is going to fall down for real-world workloads and eat away at your area and power efficiency, as various over-specified bits start to sit idle more often. Instead, you want to be more intelligent about what numbers go up and what numbers stay roughly the same, as you take the design up the performance/area curve.
That means organising the GPU internally into blocks, or groups of blocks, that can scale independently of each other inside a single GPU boundary. Pretty much every GPU design today does that, in order to maximise efficiency for the target design point, and Furian is no different.
It is different to Rogue, though. Organisational changes for Furian mean that the balance of front-end (geometry and rasterisation), core (ALUs and texturing) and back-end (pixel export to memory) is slightly less rigid. The microarchitecture achieves that with a top-level core block we call the SPU, or Scalable Processing Unit.
The SPU contains one geometry pipeline, one rasterisation pipeline, one texture pipeline (TPU), a number of Universal Shader Clusters (USCs), and up to two backend pipelines (PBEs), and Furian now scales itself one SPU at a time. There are some key bits not inside the SPU and only present once, usually, the tiler being the most notable, but computationally you should think about Furian at the SPU level.
The number of USCs per SPU give us the ability to balance the compute resources of Furian designs to meet market requirements. We’re not announcing specific Series8XT products in either configuration today, just like we did with the Rogue architecture announced in 2011, and products in 2012, but the microarchitecture supports a wide range of internal resource scaling. You might ask how that differs to 7XT-generation Rogue?
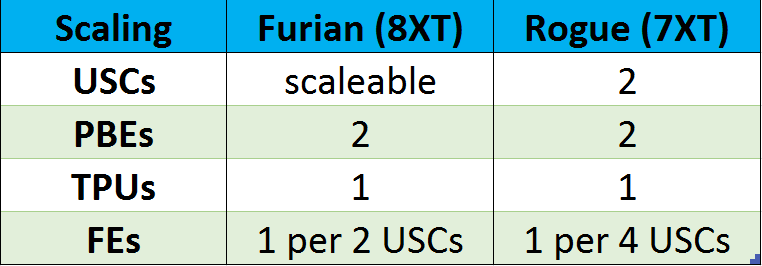
Rogue’s front-end resources (geometry and rasterisation for the most part) scaled up for every 4 USCs in 7XT. That part of the design scales up with every SPU in Furian. Similarly, back-end pipelines in Rogue were always two PBEs for every two USCs. Furian is now up to two PBEs for every SPU. We probably need a handy list at this point, centred around the number of USCs in each.
* 2-USC Rogue (7XT): 1 front-end, 1 TPU, 2 PBEs
* 2-USC Furian (8XT): 1 front-end, 1 TPU, 2 PBEs
* 4-USC Rogue (7XT): 1 front-end, 2 TPUs, 4 PBEs
* 4-USC Furian (8XT): 2 front-ends, 2 TPUs, 4 PBEs
* 6-USC Rogue (7XT): 2 front-ends, 3 TPUs, 6 PBEs
* 6-USC Furian (8XT, 2 USCs per SPU): 3 front-ends, 3 TPUs, 6 PBEs
* 6-USC Furian (8XT, 3 USCs per SPU): 2 front-ends, 2 TPUs, 4 PBEs
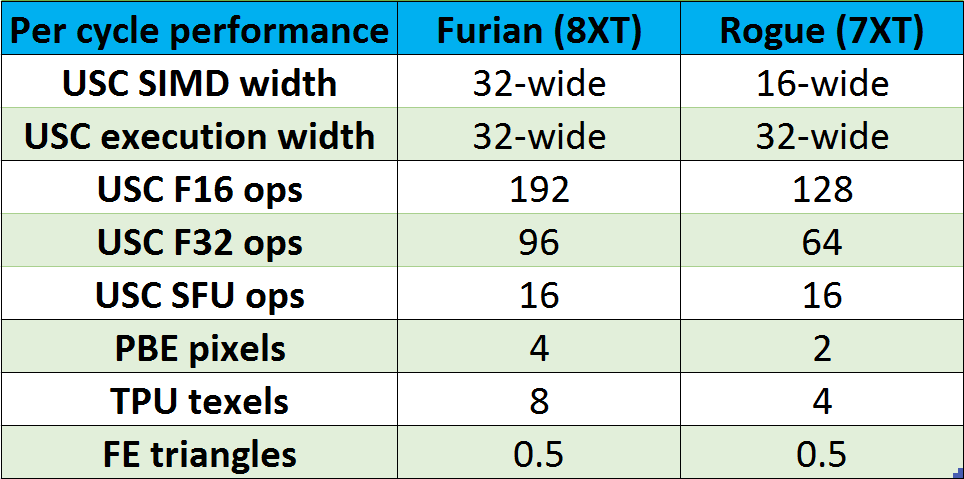
That small sample of possible example configurations paints the best picture of some of the possible per-SPU design points for Furian, dependent on the number of USCs therein. The scalability enables us to design for a wider range of target performance points compared to Rogue. Which brings me nicely on to talking about the new per-block performance of the USC, TPU and PBE.
USC
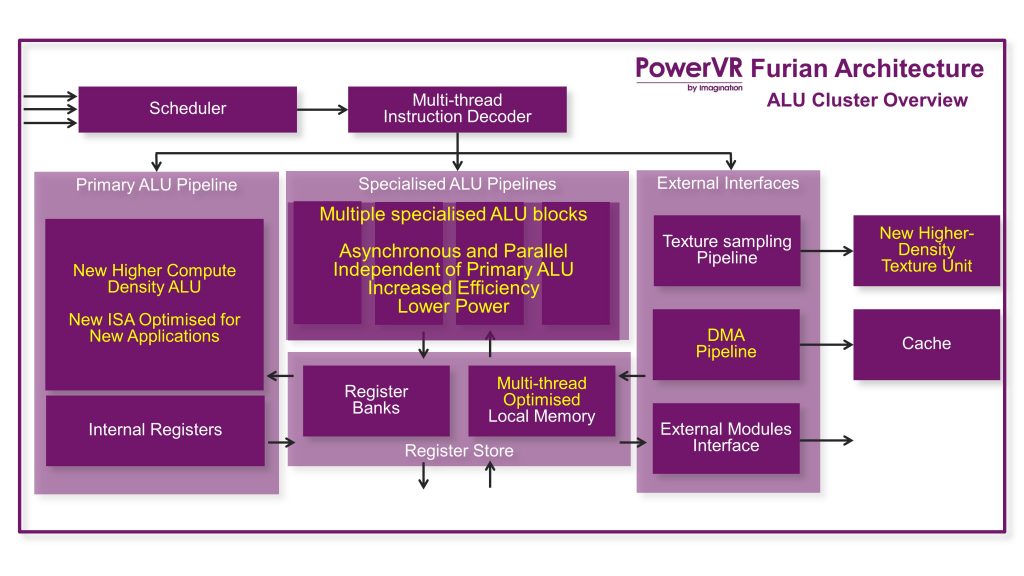
We’ve completely redesigned the USC for Furian. Where Rogue was nominally a 16-wide scalar SIMD machine, running a 32-wide task over two cycles, Furian is a 32-wide scalar SIMD machine that runs the entire task in a single cycle. We’ve also changed what executes per-clock, per-lane in the Furian USC. Rogue, for F32, could execute a pair of FMA instructions in parallel, per-clock, per-lane. Furian swaps that parallel FMA setup out for a single FMA, plus a parallel multiply, giving it 50% more arithmetic throughput per clock for the same number of USCs as Rogue.
We kept the same double-rate F16 ability that’s been in our GPU designs since the first generation of Rogues, too. The importance of great F16 performance has grown in recent years, with applications beyond graphics that are increasingly important to every GPU vendor’s customers. That means it’s no surprise that pretty much every GPU on sale today now has higher rate F16 performance via some microarchitectural mechanism, and Furian is no different, keeping a facet of performance we’ve now had for a very long time.
As you can see, Furian extends Rogue’s specialised pipeline idea. Rather than shoehorning everything the core can do, computationally, into a single monolithic pipe, we keep things simpler, while still sharing as much as we can to control the separate paths. When it comes to deciding what kind of instruction needs to run, the USC control logic decodes an incoming instruction bundle, figures out what’s going to run and where the data to run it is going to come from, and dispatches that all to the correct set of pipelines, cycle-by-cycle. There’s also co-issue opportunity inside the USC at the pipeline level, so the top-level logic figures out data flow and what needs to run, every clock. That means it’s possible for multiple pipelines to be working at the same time, per-USC, with the main intent being to keep the PIP fed and busy all the time.
The USC is therefore conceptually a set of memories, a scheduler and associated top-level control logic, and a bunch of specialised computational and data flow pipelines that can come into play whenever they’re required, simultaneously wherever possible.
TPU and PBE
There’s not much to say on the Furian TPU. Oh, except that it’s got double the filtering throughput compared to the TPU on Rogue. Peak INT8 bilinear sample rate is now 8 samples per clock for the Furian texture hardware. Remember the TPU is shared between the USCs in the SPU. The USCs make requests into the TPU as they need data, and from then on the TPU logic works on those requests. The TPU is free to re-order work between each USC, but obviously returns data back to the USC in the order that USC requested it.
And yep, you guessed it: to keep pace with the TPU performance increase, the PBE is also capable of twice the export rate compared to the Rogue PBE. With two per SPU, each SPU can emit a peak of 8 pixels per clock (so 256 bits) into the memory fabric. Connecting each Furian to the outside world is a set of 256-bit ACE interfaces, needed for today’s high-end system-on-chip designs. Peak GPU-to-system bandwidth is therefore quite a bit higher than you might expect from devices that will end up in your hand, or integrated into something like your car, and so it’s necessary to keep such a high-performance GPU fed and watered with everything it needs to sustain the target performance level.
 Memories and memory hierarchy
Memories and memory hierarchy
Speaking of memory, internally to the USC, there’s been a complete redesign of the memories the USC can read from and write to, to make them more efficient. We’ve always had a few separate register pools inside the USC, for registers with different purposes, but Furian specialises a couple of extra register types that warranted attention. Rather than building a completely unified register file for all possible data access inside the USC, keeping specialised pools lets us more easily avoid bottlenecks and optimise the power of the design too.
We’ve also completely redesigned Furian’s overall memory hierarchy, from register stores all the way up to the final System Level Cache at the boundary between it and the ACE ports I mentioned earlier. We did that partly because of the new way Furian scales, but also to make it much more efficient in certain spots, to avoid bottlenecks and let the design essentially breathe more freely. There’s too much detail to go into there, really, but the TPU, and how good the overall design is at bindless rendering, were a particular focus for that work.
Work in this area also significantly benefits future Furian-based designs that implement our incredible ray-tracing technology. While talking to the architecture teams throughout Furian development, and even while doing final research for what to write here, it was crystal clear that Furian has its ray-tracing family members clearly in mind from the very start. Keep your eyes peeled for a Furian-based ray-tracing microarchitecture in the future!
Summary
That’s quite a lot of new information to take in about Furian’s major microarchitectural highlights, so let me sum it up quickly before we take a look at a couple of tables of numbers to digest that shows you exactly where performance has improved per-clock and how the design scales. I do the architects and designers a real disservice here of course; the totality of changes between Furian and Rogue in the microarchitecture could easily keep someone busy writing explanatory articles for the blog for months.
So: Furian scales in a new way, using the new SPU as the building block to gather specific GPU resources together, both conceptually and physically in silicon in layout. We can vary the processing resources per SPU, enabling us to fine-tune the balance of the core depending on our customer’s requirements, while still keeping it easy for physical teams to layout in their overall system design. The new per-SPU performance of the front-end, texturing, and back-end logic means that Furian also scales to new levels of overall GPU performance outside of the computational aspect of the USC.
The USC itself is now at least 50% more powerful per clock, more efficient in its use of the primary arithmetic pipeline and the other specialised pipes alongside it, and has a completely redesigned internal memory organisation, feeding in to Furian’s new memory hierarchy as a whole. It was architected for much higher efficiency in the design, and for scaling that new SPU structure into bigger GPU configurations.
Furian is, therefore, is a brand-new microarchitecture that tackles the business of being a really great general purpose compute core, surrounded by best-in-class GPU-specific resources that continue to embody PowerVR’s specific TBDR design philosophy, combining to create a big leap forward from Rogue. For us, it doesn’t matter if the USC or TPU changes completely, or the way that the GPU is put together at the block level evolves in a new direction that scales differently to before; if our TBDR execution is at the heart of the design, it’s definitively a PowerVR GPU.
We couldn’t be more excited to finally tell everyone a bit more about it, leading into specific product announcements as soon as they’re ready.
For the latest news and announcements on PowerVR don’t forget to follow us on social media; on Twitter @ImaginationTech, LinkedIn, and Facebook.