


Last year, Imagination announced Furian, our newest graphics architecture and the first major update for PowerVR since 2012. This introduction marks a significant step in satisfying the ever increasing demands for more device performance, especially for new use cases such as AR, VR, and AI, while keeping PowerVR at the top of the pile for power efficiency and performance in embedded GPUs.
Furian was designed with scalability in mind, ensuring that performance and area efficiency remains consistent regardless of the number of scalable processing units (SPUs) that are laid down. In this post, we will be focussing specifically on the power efficiency of the architecture and how this ensures that it remains ahead of rivals' designs for performance per watt.

Following the arrival of the Furian architecture, we announced the first Furian-based core available for licence – the PowerVR GT8525 and we have now announced the PowerVR GT8540 – a four cluster variant aimed at the premium mobile and automotive markets.
Compared to the multi-core designs currently shipping in high-end smartphones and tablets, the single scalable processing unit (SPU) – containing what we describe as two-clusters, in the PowerVR GT8525 could be considered a fairly modest option to launch as the first GPU available to licence. However, it should not be underestimated. The performance of this single SPU design is a testament to how far Furian has moved the game on.
This is because by far the bulk of the potential smartphone market is in the category that some parts of the industry refer to as ‘super-mid’. As technology enthusiasts that make industry-leading graphics designs, we at Imagination are always going to be fans of premium products. Indeed, many of us carry high-end devices in our pockets featuring no-compromise performance. However, these types of devices are undoubtedly expensive and increasingly it can be argued that for most people lower-cost, more sensibly priced devices, offer enough capability for almost everyone. In large part this is precisely down to GPUs such as the PowerVR GT8525.
For many, a sensibly priced device offers enough power to comfortably handle day-to-day tasks, such as browsing the web, checking social media, and also playing visually complex games smoothly. They are even good enough for users to dabble in new types of experiences such as AR, VR, and AI-based applications. What’s more, the SoCs in mid-range devices don’t traditionally use leading-edge manufacturing processes, which will limit the power budget they can spend, and thus the use of a smaller GPU will be preferable. That being the case, this makes the release of the PowerVR GT8525 an ideal GPU for SoC vendors to license, thanks to its ideal balance between efficiency and performance.
Architected for efficiency
What really enables us to stay ahead of the curve when it comes to power efficiency, though, are the changes and enhancements in Furian that build on the work already done with Rogue. These changes were made to optimise internal efficiency, which inherently has the benefits of offering more performance for a given power consumption point.
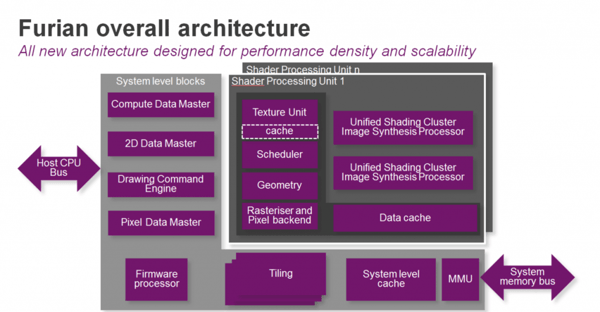
More efficient SPU
One of the changes is inside the scalable processing units, which have been re-architected to be more area efficient with much higher utilisation of the Arithmetic Logic Unit (ALU). As the block diagram above indicates, the texture unit now has its own cache, ensuring that it doesn’t have to compete with the Unified Shading Clusters (USCs) for access to the data – the result is higher throughput efficiency with lower power. The texture unit now delivers double the fill-rate over the previous design at eight pixels per clock, for only a modest increase in area.
The 2D Data Master
Another enhancement, first introduced with Series7XT, and enhanced further here, concerns the 2D Data Master. It’s now fully asynchronous, enabling better utilisation of the core, also delivering better power efficiency. This enables the independent submission of 2D workloads, bypassing all tiling overhead (e.g. when doing 2D using 3D calls) making it much more efficient for things such as creating UIs – and again this helps to reduce power consumption.
Doubling the pipe flow
And yet another major enhancement to overall efficiency stems from the changes made to the primary ALU pipelines (see the diagram below). This has doubled in width from 16 to 32 pipelines – delivering twice the throughput per clock. What’s key though is that it does not take up twice the silicon area thanks to streamlining of the internal design and more shared control logic. In Rogue, the pipelines contained two Multiply Adds function blocks (MADs). However, after close analysis of the shader and kernel code typically written by developers, it became apparent that these two MADs were rarely being fully utilised, as using two together proved difficult for the compiler.
Therefore, with Furian we instead implemented a MAD and a MUL, offering more performance in the real world, while keeping silicon area cost in check. And in scenarios where two MAD operations are actually required, Furian’s double-width pipeline enables it to match Rogue’s performance (16×2 MADs = 32×1 MAD), so in that sense at worst, nothing has been lost over the previous approach and most of the time, throughput is significantly increased.
Reducing latency
The changes don’t end there. The function calls between the GPU driver and the GPU for compute, now no longer have to go through the OS kernel layer. They now use something called ‘user mode queues’ to communicate directly, reducing overhead and latency, in turn again reducing power consumption.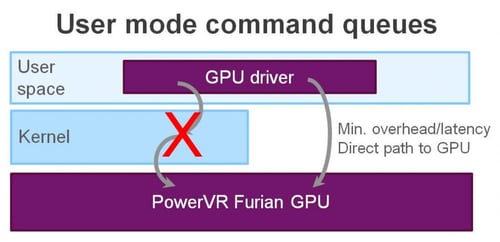
Additionally, the GPU now supports improved simultaneous access to more local memory addresses, which means each ALU pipeline can directly access the memory areas they need without stalls.
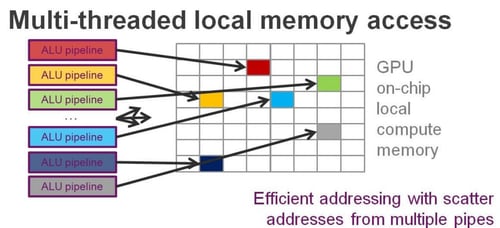
The result
So what are the results of all these changes? As we can see from the graph below, in the popular industry standard Kishonti GFXBench Manhattan 3.0 benchmark, the Series8XT GT8525 offers significantly more frames per second (fps) per watt, or fps/W, than our PowerVR GT7450, our previous generation equivalent GPU hitting around 35fps compared to 15fps previously. (‘Frames per second’ refers to how smoothly a game might run on a device, so the higher number the better for the end-user experience). That it does so in a smaller silicon area (as indicated by the smaller circle) is an additional benefit.
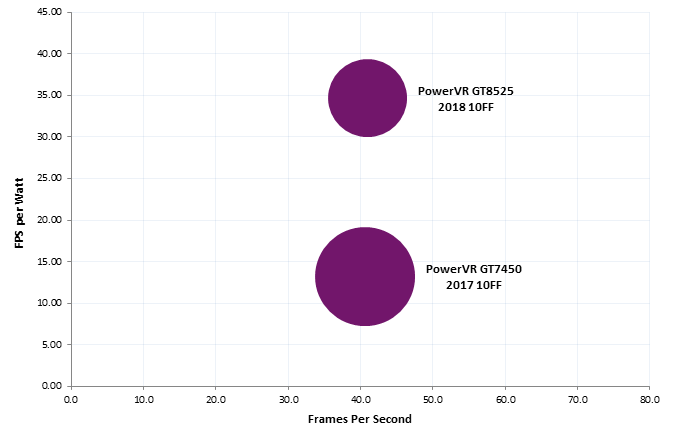
PowerVR GT8525 vs GT7450 – Manhattan 3.0 FPS vs FPS/W and Area
While power efficiency is an important aggregate measurement metric of a GPU, what matters equally is the absolute power consumption. Mobile devices are limited to an SoC thermal envelope of 3-3.5W. Of that number, the GPU accounts for 30-50% of the power consumption. At an estimated 35fps/W, a Series8XT GT8525 in a mid-range SoC manufactured on TSMC’s 10FF process falls in the sweet-spot of under 1.5W of power for the GPU.
To put it into perspective, against our previous generation Series7XT, we expect that for the same performance target (iso-performance), a Series8XT GT8525 will use up to 60% less power against a comparable Series7XT GT7450, meaning the performance/W goes up to an incredible 75%! For the end user, this means that they will be able to enjoy a device that will last for longer, especially when under load, such as when gaming.
Of course, our industry-leading power efficiency is built on the use of our legendary tile-based deferred rendering (TDBR) technique, where we only render the pixels that will be seen on the screen and as ever, this is what Furian is based on. If you’d like to know more, do check out our older blog posts that go in-depth on TBDR.
Conclusion
As you can see then from all these changes introduced in the Furian architecture, the PowerVR Series8XT GT8525 offers highly effective performance at cost-effective prices, raising the bar for devices in a wide range of markets. We have already licensed our first Series8XT core to key customers, and we look forward to adding to that list in 2018.
Remember to keep up to date you can follow us on social media on Twitter @ImaginationTech and on LinkedIn, Facebook.



